Large multimodal models have demonstrated impressive problem-solving abilities in vision and language
tasks, and have the potential to encode extensive world knowledge. However, it remains an open challenge
for these models to perceive, reason, plan, and act in realistic environments. In this work, we
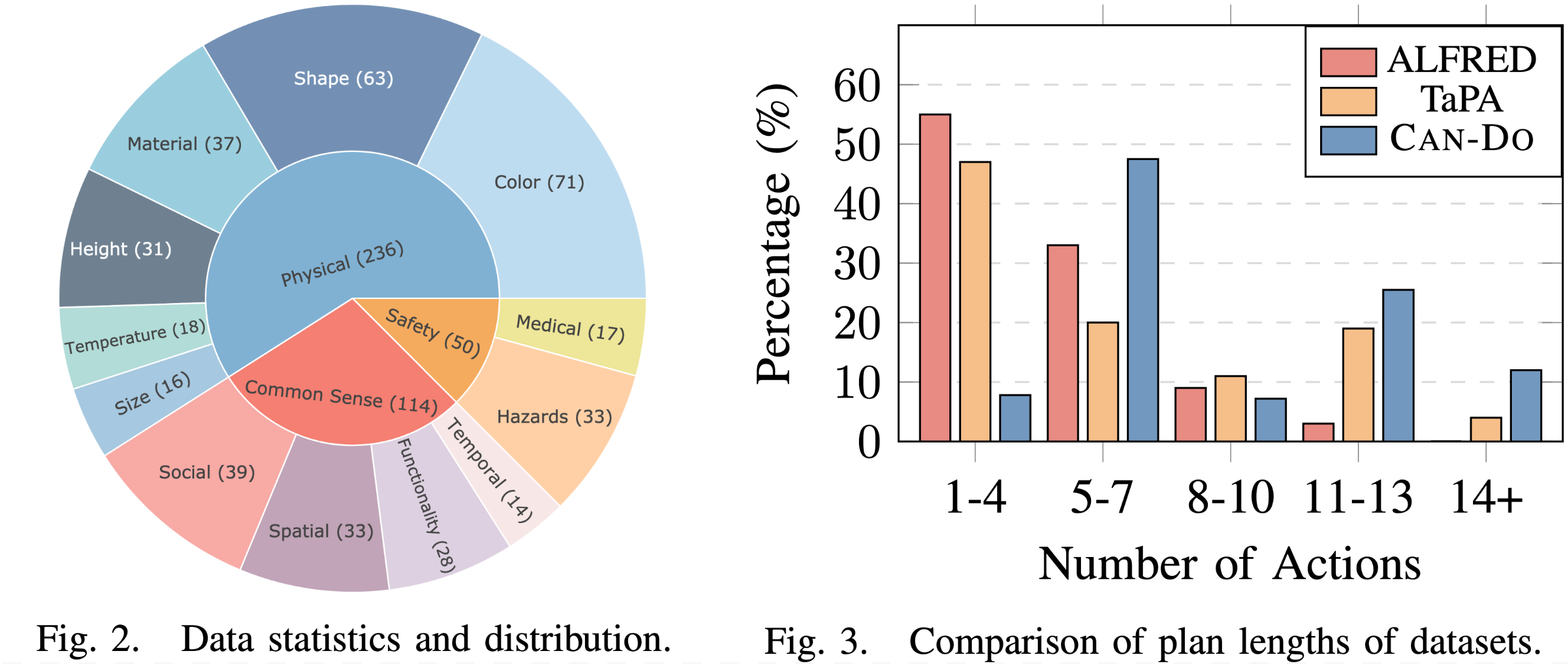
introduce Can-Do, a benchmark dataset designed to evaluate embodied planning abilities through more
diverse and complex scenarios than previous datasets. Our dataset includes 400 multimodal samples, each
consisting of natural language user instructions, visual images depicting the environment, state
changes, and corresponding action plans. The data encompasses diverse aspects of commonsense knowledge,
physical understanding, and safety awareness. Our fine-grained analysis reveals that state-of-the-art
models, including GPT-4V, face bottlenecks in visual perception, comprehension, and reasoning abilities.
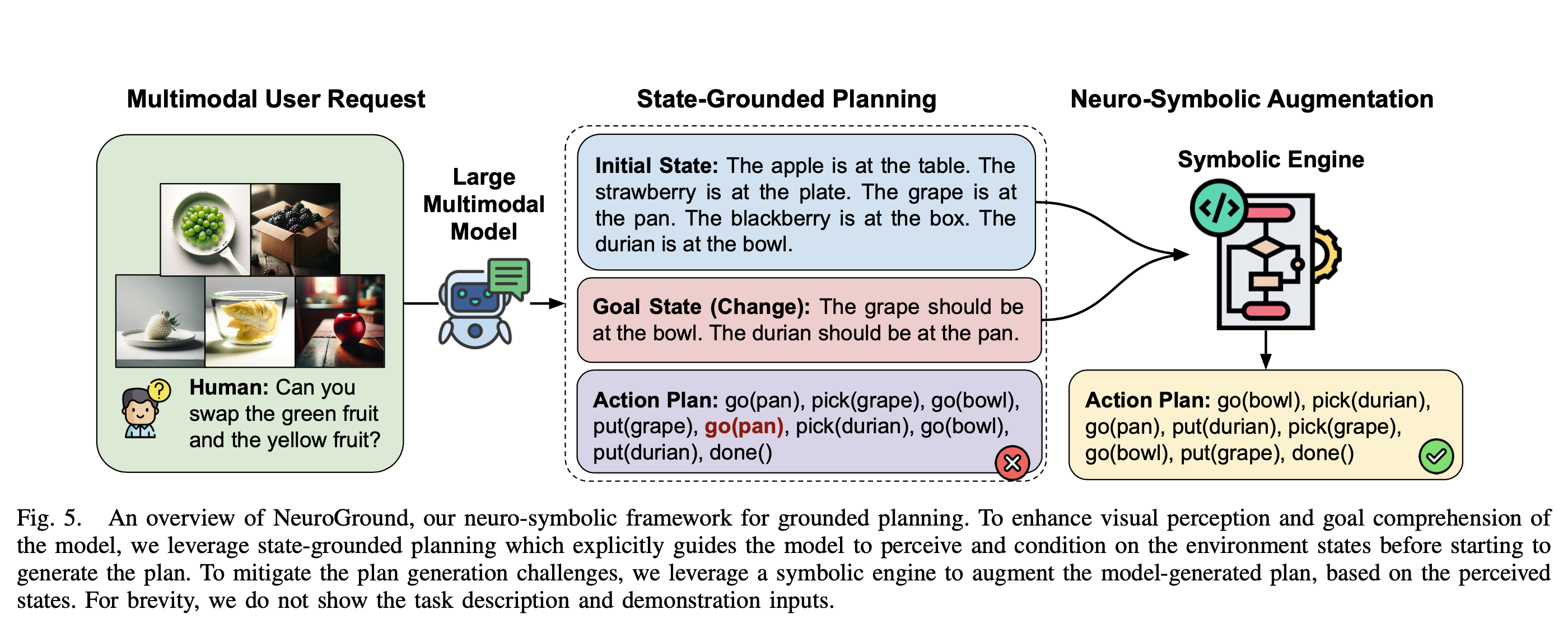
To address these challenges, we propose NeuroGround, a neuro-symbolic framework that first grounds the
plan generation in the perceived environment states and then leverages symbolic planning engines to
augment the model-generated plans. Experimental results demonstrate the effectiveness of our framework
compared to strong baselines.
Based on our preliminary study, which diagnosed significant planning bottlenecks in visual
perception, goal comprehension, and reasoning for plan generation, we propose NeuroGround, a
neuro-symbolic framework for grounded embodied planning. To enhance the visual perception and
comprehension ability of the model, we leverage state-grounded planning which explicitly guides the
model to generate and condition on the environment states before starting to generate the plan. To
mitigate the plan generation limitations of the model, we augment it with a symbolic engine, inspired by
neuro-symbolic approaches. In this way, our framework is able to enhance the planning ability of large
multimodal models.
Inspired by our work, Varshith and Prof Pablo from SUTD have implemented a robot demonstration with our
planning algorithms. Here, the robot arm with soft gripper is tasked to prepare a salad bowl based on
the the following
prompt: "make me a protein rich salad in the empty white bowl, I'm lactose intolerant, make the salad
spicy".